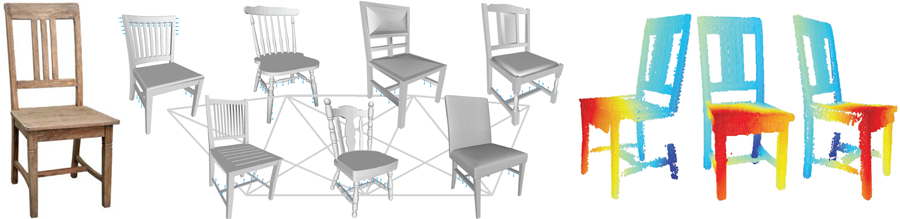
We attribute a single 2D image of an object (left) with depth by transporting information from a 3D shape deformation subspace
learned by analyzing a network of related but different shapes (middle). For visualization, we color code the estimated depth with values
increasing from red to blue (right).
Estimating Image Depth Using Shape Collections
Hao Su, Qixing Huang, Niloy J. Mitra, Yangyan Li, Leonidas Guibas
Siggraph 2014
Abstract:
Images, while easy to acquire, view, publish, and share, they lack
critical depth information. This poses a serious bottleneck for many
image manipulation, editing, and retrieval tasks. In this paper we
consider the problem of adding depth to an image of an object, effectively
‘lifting’ it back to 3D, by exploiting a collection of aligned
3D models of related objects shape. Our key insight is that, even
when the imaged object is not contained in the shape collection,
the network of shapes implicitly characterizes a shape-specific deformation
subspace that regularizes the problem and enables robust
diffusion of depth information from the shape collection to the input
image. We evaluate our fully automatic approach on diverse and
challenging input images, validate the results against Kinect depth
readings, and demonstrate several imaging applications including
depth-enhanced image editing and image relighting.
Results:
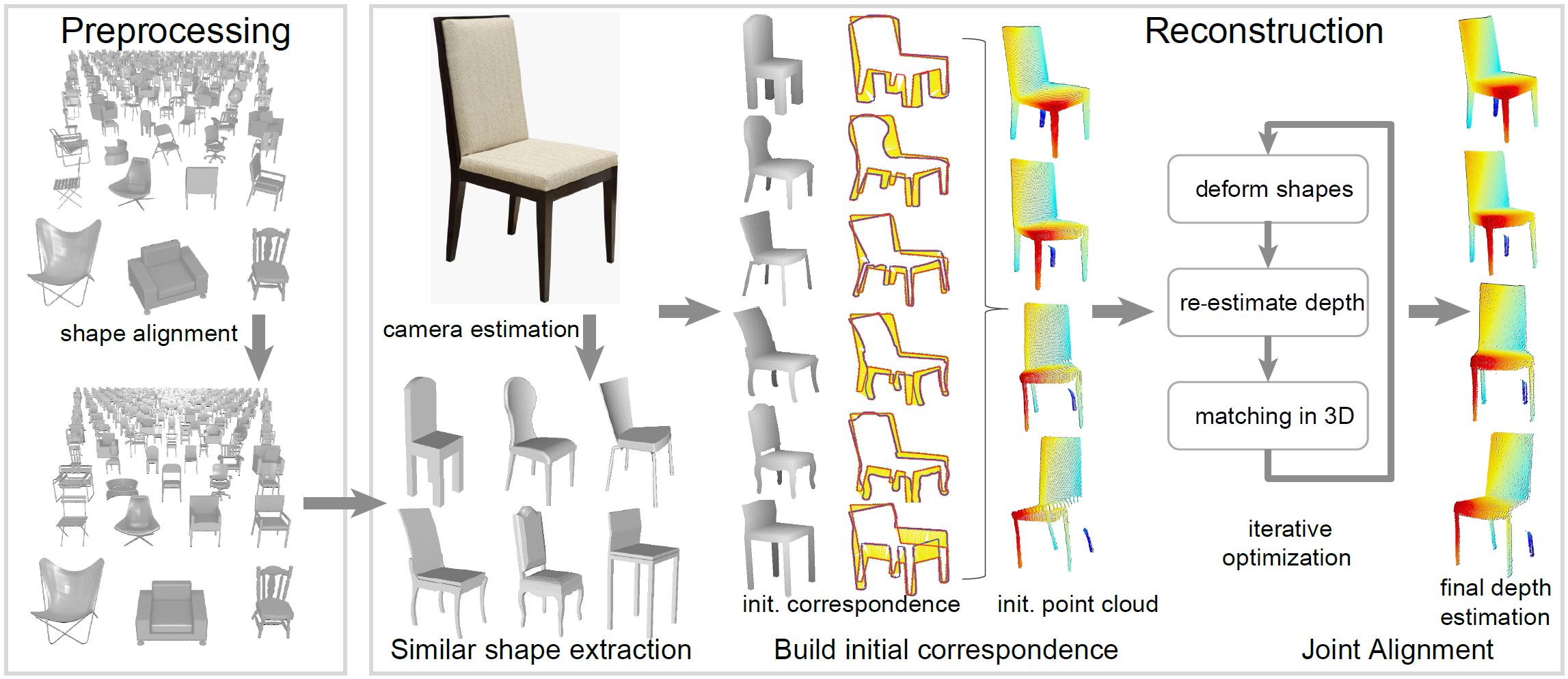
We reconstruct a 3D point cloud from an image object by utilizing a collection of related shapes. In the
preprocessing stage, we jointly align the input shape collection and learn structure-preserving deformation models for the shapes. Then,
in the reconstruction stage, we lift a single image to 3D in three steps. The first step initializes the camera pose in the coordinate system
associated with the aligned shapes and extracts a set of similar shapes. The second step performs image-image matching to build dense
correspondences between the image object and the similar shapes, and generate an initial 3D point cloud. The final step jointly aligns
the initial point cloud and the selected shapes by simultaneously optimizing the depth of each image pixel, the camera pose, and the shape
deformations.
We have evaluated our approach on five categories of objects. This figure shows representative results
in each category. For every object we show the input 2D image, the extracted similar shapes, the reconstructed point cloud and finally the
ground truth Kinect scan, shown on the right column for reference.
Top: point clouds viewed from different angles. Bottom: surface
reconstruction results with symmetry-based completion.
Using the inferred depth information, we
can build the normal map and simulate different lighting conditions.
Leftmost column is the input image and the three columns on
the right are the simulated illumination. A directional light source
moves from left to right (top row), or up to down (bottom row).
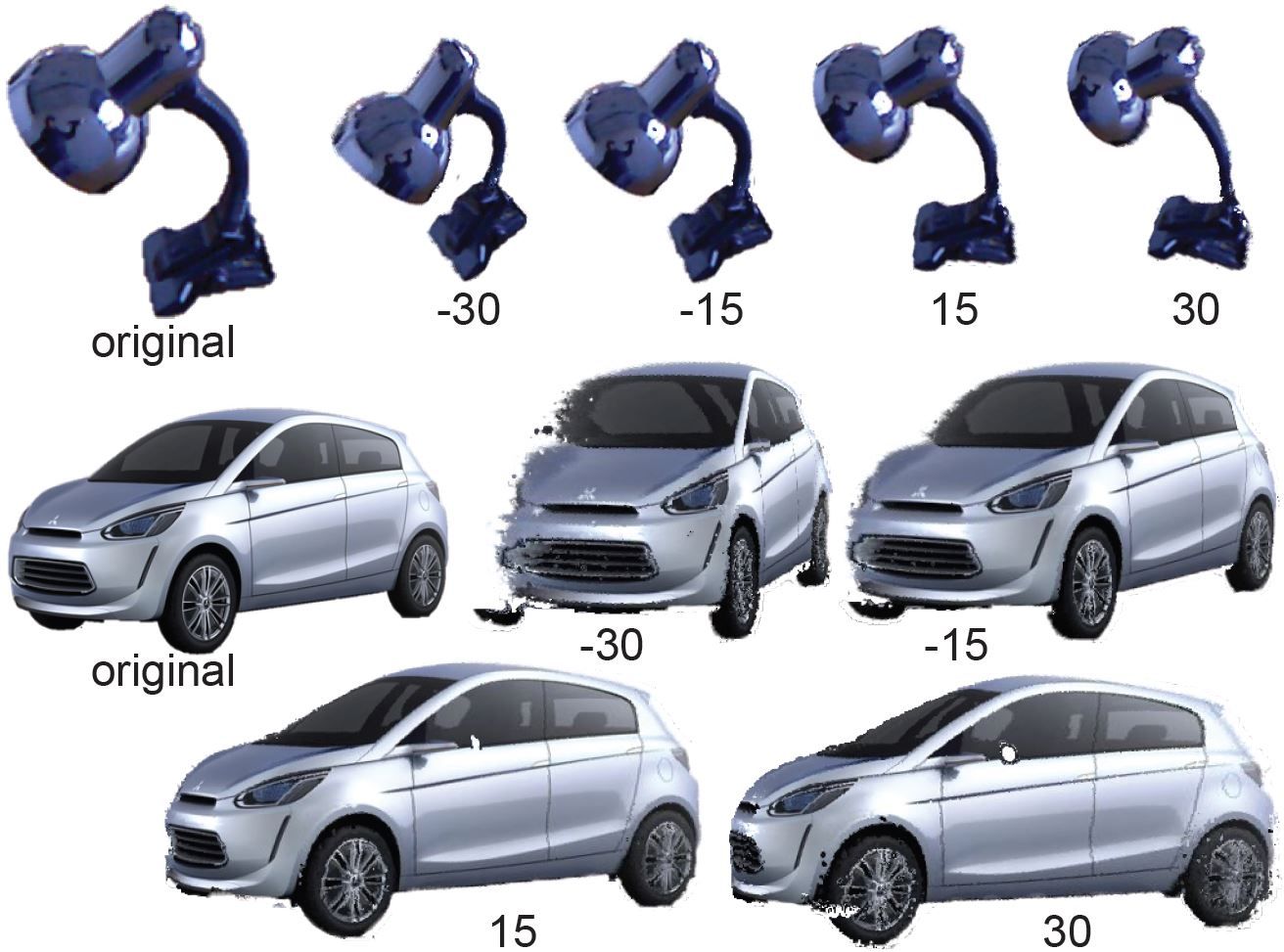
Simulated images by rotating
cameras around the y-axis (up-direction).
We thank the reviewers for their comments
and suggestions on the paper. This work was supported in part
by NSF grants IIS 1016324 and DMS 1228304, AFOSR grant
FA9550-12-1-0372, NSFC grant 61202221, the Max Plack Center
for Visual Computing and Communications, Google and Motorola
research awards, a gift from HTC corporation, the Marie Curie Career
Integration Grant 303541, the ERC Starting Grant SmartGeometry
(StG-2013-335373), and gifts from Adobe.
Bibtex:
@article{shmlg_imageDepth_sig14,
AUTHOR = "Hao Su and Qixing Huang and Niloy J. Mitra and Yangyan Li and Leonidas Guibas",
TITLE = "Estimating Image Depth Using Shape Collections",
JOURNAL = "Transactions on Graphics (Special issue of SIGGRAPH 2014)",
YEAR = "2014",
numpages = {11},
}